json和pickle序列化和反序列化
json是用来实现不同程序之间的文件交互,由于不同程序之间需要进行文件信息交互,由于用python写的代码可能要与其他语言写的代码进行数据传输,json支持所有程序之间的交互,json将取代XML,由于XML格式稍微比较复杂。现在程序之间的交互都是用json来进行文件信息的交互。
在使用json序列化和反序列化的时候,dump一次,就要load一次,不能操作。
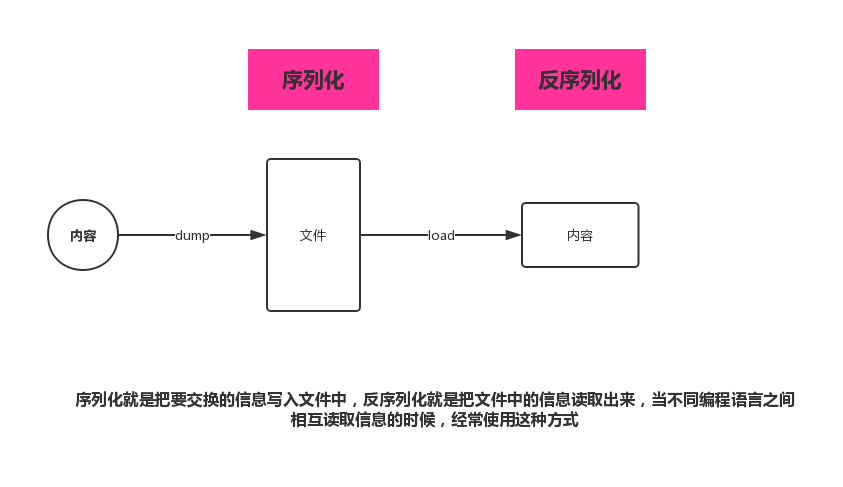
json序列化的过程,就是写入文件中,让另外一个编程语言进行调用:
import json info = { "alex":"sb","test":"hard"} with open("file","w") as f: f.write(json.dumps(info))
上述代码使用json将info字典信息写入到一个文件中,文件中只能存储字符串格式的信息,或者二进制文件的信息,不能存放数字等信息,放入文件中的信息都是字符串类型的,这点一定要注意.
json反序列化的过程:
import json '''反序列化起始就是把dump进去的信息进行提取,以实现不同编程语言的交互''' with open("file","r") as f: data = json.loads(f.read()) print(data) print(type(data)) print(data["alex"])
上面代码,将使用json格式存入的信息读取出来,如下所示:
{'test': 'hard', 'alex': 'sb'} <class 'dict'> sb 上述代码实现了将字符串信息读取问字典的功能,其实,序列化和反序列化就是将原来的格式先转化为字符串,然后在读取出来的过程,以便能够实现交互.
我们也可以使用其他方式进行序列化和反序列化,我们知道,有一个函数eval(),能够实现把字符串信息转化为原本样式,如下:
info = [11,22,33,65,33] with open("test.text","w") as f: f.write(str(info)) #使用wirte()只能向文件中写入字符串格式的信息,不能写入其他类型的信息 with open("test.text","r") as f_obj: data = f_obj.read() data = eval(data) print(type(data)) print(data)
程序运行如下:
<class 'list'> [11, 22, 33, 65, 33] 上述过程中,我们利用python自带的eval()函数也实现了序列化和反序列化的过程,但是由于序列化和反序列化是在同一个程序中实现的,在其他程序中有没有eval()是不确定的,但是json支持所有的编程语言,所以现在一般都使用json实现不同编程语言之间的信息交互.
dump和load也是实现上面dumps和loads的功能,只是实现的方式不一样而言,语法稍微有一些区别,如下:
dump序列化:
import json info = { "alex":"sb","test":"hard"} with open("file","w") as f: json.dump(info,f)
load()反序列化:
import json '''反序列化起始就是把dump进去的信息进行提取,以实现不同编程语言的交互''' with open("file","r") as f: data = json.load(f) print(data) print(type(data)) print(data["alex"])
上面程序实现了序列化和反序列化的功能,dump(信息,文件路径),load(文件路径),从哪个文件读取信息.
在不同程序间实现数据的交换.
不同程序之间的数据交换,或者是将字符串的信息转化为原有的形式;
eval()函数的功能也很强大,能够之间将字符串形式的信息转化为原有的信息,如下:
>>> dic = "{'alex':'sb','try':'workhard'}" >>> data = eval(dic) >>> data {'try': 'workhard', 'alex': 'sb'}
程序只dump一次,load一次,不能dump多次.dumps好几个文件实现;